The data and artificial intelligence (AI) firm DataPebbles has joined the SBIC partner network and is available to provide technical support to our ESA BIC startups. This could be anything from implementing data toolsets to the provision of a responsible AI development platform for creating machine learning models.

We chatted to founder Surajeet Bhuinya to find out what DataPebbles can offer to our community. At the outset, in relation to processing the date from satellite images, he emphasises the need for efficient machine learning models – and, importantly, a quick and continuous approach to put them into production and get validation. It is the overview of such data in combination with local monitoring on Earth that can gives an added value and in the long run contribute to sustainable actions for the planet.
What is at the heart of your business?
At DataPebbles, we advise on technological choices and architecture, provide complex data processing and dashboard solutions, and assist and advise on machine learning model development. In essence, we provide software engineering best practices and end-to-end data solutions. So, we don’t just work with a certain part, like only creating a visualisation report or only formulating a machine learning model, but we do everything.
How can you help our community?
We want to help startups reach their goals. These startups might not have expertise in all technologies required for big data. Whenever you talk about a machine learning model, the data is not just creating the model that works on the laptop. It also has to have the ability to scale and that is the kind of skill that we provide. At DataPebbles, we try to help our partners to be more sustainable. It’s not like that from day one they should be focusing on producing efficient code. We can come in and help them to get started with that. Then, slowly we help them to also develop these skills to continue on their own in this area. So, that’s the kind of relationship I want with the startups. We work with them and help them to reach their goals faster. Importantly, they only get help up to a certain level, after which they continue growing in that space by themselves. We don’t have to do all the basic things, as they should be able to do this over a period of time.
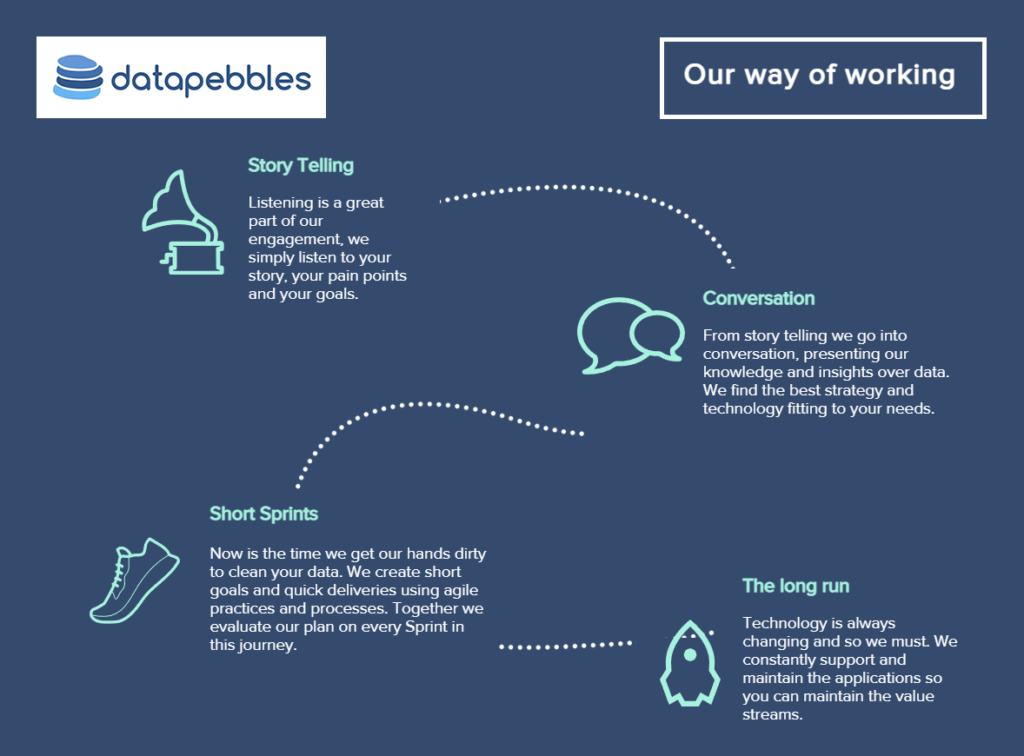
What approach do you and your team take?
We start with a discussion: you tell us your problem and we will talk more about your data and try to understand the data from your perspective. From that data, we generate the features required to create a machine learning model. The model, after evaluation, testing, etc., is then deployed in production, after which we help you to support all this pipeline. Everything is done in a very cloud-native way and that’s where our end-to-end offering comes in, because it’s very difficult to find people who have knowledge of the cloud platform Kubernetes (an open-source system for automating deployment, scaling and management) and we have that knowledge and expertise. You don’t need to master it.
What recent developments in your company will benefit the SBIC community partnership?
Our team is experienced in machine learning operations (ML ops) and our focus area is creating qualitative training data sets for machine learning models, which we offer via an online platform. This platform has aspects of a responsible AI development with already in-built features that are: compliant; explainable; and ethical. For compliance, you can create rules that set certain boundaries. In relation to the explainable aspect of the platform, we do all data quality checks and are transparent in relation to the recommendations the system makes for the attributes used in the training data set. In terms of ethicalness, we can show aspects of the data that helps anybody to understand whether it’s biased or not. In future releases of the platform, there will be more features available in all the three verticals.
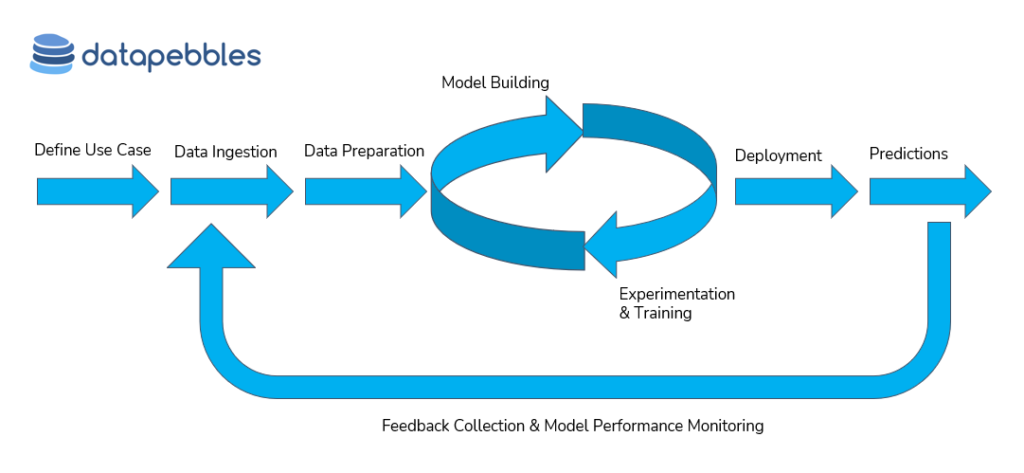
What technical support can the ESA BIC startups make use of?
There are two propositions that we have for startups. The first is to provide support to build their platform or whatever model they require for their applications from a pure data perspective. So, we can come and help that startup in terms of engineering augmentation. We can also help them if they need expertise for a one-time job for a data engineering solution. This first proposition is more like a consultancy and partnership to support them to reach their goals.
The second is more of a long-term relationship and includes our own responsible AI data platform, which the startups can make use of to create their own machine learning models. They can decide how much or how little they make use of the platform, as it’s designed in a very modular way with three parts in the same platform – it’s more like LEGO bricks and you choose which components to make use of. If you are just interested in doing data transformation to see how the data looks, you can use that part of the platform – or if you just want to ensure that your data is good quality and extract visualisations, you would use the verification module. Then, there is the part that covers the machine learning model. Here, you can opt to do some feature engineering to create your training data set and to train the model. So practically, if you have good knowledge of your data, you can sign up to our platform and say, “I know this is the data set and I want to create this model. I know the algorithm but I don’t have cloud servers to run this algorithm or the expertise of doing the data preparation analysis. And I don’t know how to run an API to serve my model.” If you recognise yourself in this scenario, our platform is the best fit – it is very user friendly and you can input your queries in a very non-technical way.
Can you help with setting up data toolsets?
Yes. Some startups might need help to set up their first data computation framework. These data toolsets can be small or big, it doesn’t matter; it can be in the cloud or it can be local. They can use these data toolsets without learning how to implement them, as that’s where we can help out. And that’s why the data pipeline comes into the picture, because once you have the pipeline ready, you don’t want to recreate the same thing again – everything should be automated. So, once it’s there, you can keep on using it.
What’s the first step for our startups to reach out?
We are a team of six people based in Leiden and I will be the first point of contact for any of the entrepreneurs wishing to make use of our technical support. My team generally likes to focus more on the problem set and that’s why the structure is like this – it’s very flat to be very honest. I’m on the front layer and then everybody is on at the same level as me. So, I’ll have a first meeting with the startup to see how we can help and then make a plan, which I’ll next discuss with my team for everyone to give input about the various options. It is a two-way, collaborative process and any startup is welcome to come to our office and sit with the team and chat with them directly. It has to be a joint collaboration and that’s the real partnership.

What draws you to our space business community?
I think it is interesting to know what these startups are doing. The more we interact, we can find out what the problems are and what challenges they face, and then we can provide solutions. I actually found out about SBIC by going to a talk by UbiOps (SBIC community partner) and that is where I met Alexandre Larroumets from ESA BIC startup Meteory, from whom I learnt more about the space business community in Noordwijk. All startups have different requirements but those that are not sure of the fundamental software side of things or have the experience to build a proper scalable environment like we do. This is the advantage for the startups – that they don’t have to have the knowledge themselves, they can get help and technical support from us.
Is it important that machine readable data is FAIR (findable, accessible, interoperable and reproducible) for automated processing?
I think standardisation is very important. When I was in software world, I used to say that if you don’t want to keep on doing the same boring job, you have to automate it and to automate you have to have a standard. You cannot do automation on random things, you have to have a format. There are file formats for big data for a reason – because big data has moved from traditional databases towards being machine readable and capable of being interlinked with other data in knowledge graphs (i.e. organising information in a structured way by explicitly describing the relations among entities), etc. The data is the core, which is immutable. So, you can change the data, but it only creates a new version of it. That’s the advantage of big data revolution – that with modern data stacks, we create data as separate entities. You can read it the way you want to. The file format is very efficient for big data operations, which is not possible using the basic software for data manipulations, like Excel. If you want to do automation, you need technologies that can deal with the growth of your data. I worked with companies where they had Excel formulae that took 2 days to run and create the report for compliancy; my team went in there and created automated jobs that took 6 minutes. It’s just the power of cloud computing.
How important is sustainability to you?
From my point of view, in the data world, automation is sustainability; it is the only way of establishing sustainable processes. Automation means you can free up your time, become more efficient and do away with rudimentary tasks – these tasks can be carried out by our platform. For the highly specialised tasks, of course you still need the right person in the right place. In my eyes, that is sustainability because you can keep on doing it.
From the environmental perspective, we need sustainability to be able to achieve our goals and this is accelerated through innovation. Of course, there are different way of looking at it, but looking to space is a good start because of the innovation that happens there in particular relating to the space tech required for resilient products, which can survive just about anything.
What prompted your interest in space?
I am very interested in how these startups are using space technology for our benefit here on Earth, as we need to look after the planet. When I was younger in India, we used to go to the northern region near the Himalayas where it was so dark and I would just sit and watch the constellations. I am also really drawn to the moon, with it being the clearest celestial object visible to the naked eye. It really puts things into perspective and makes me realise about what we have on Earth. We have everything we need here and yet people are trying to get to Mars. I think space tech should be used for making our Earth a better place rather than just finding a different planet [to live on]. I feel strongly that we should first see what we can do here and how we can help this world. That’s why I’m interested to find out more about how the startups’ solutions aim to solve terrestrial problems using satellite imagery and data.
The ESA BIC incubatees can join the DataPebbles info session on September 12 to discover all about the technical support available to the space business startups.
We can confirm that having a chat by the satellite at SBIC Noordwijk is great for networking – here is Surajeet of DataPebbles talking to Sean of ESA BIC startup Ecosmic at the May 2023 Network & Drinks community event.

Getting in touch with DataPebbles
Contact: Surajeet Bhuinya
Email: sbhuinya@datapebbles.com
Website: datapebbles.com
[Datapebbles stopped as technical partner in mid-2024 & continues as community partner]

